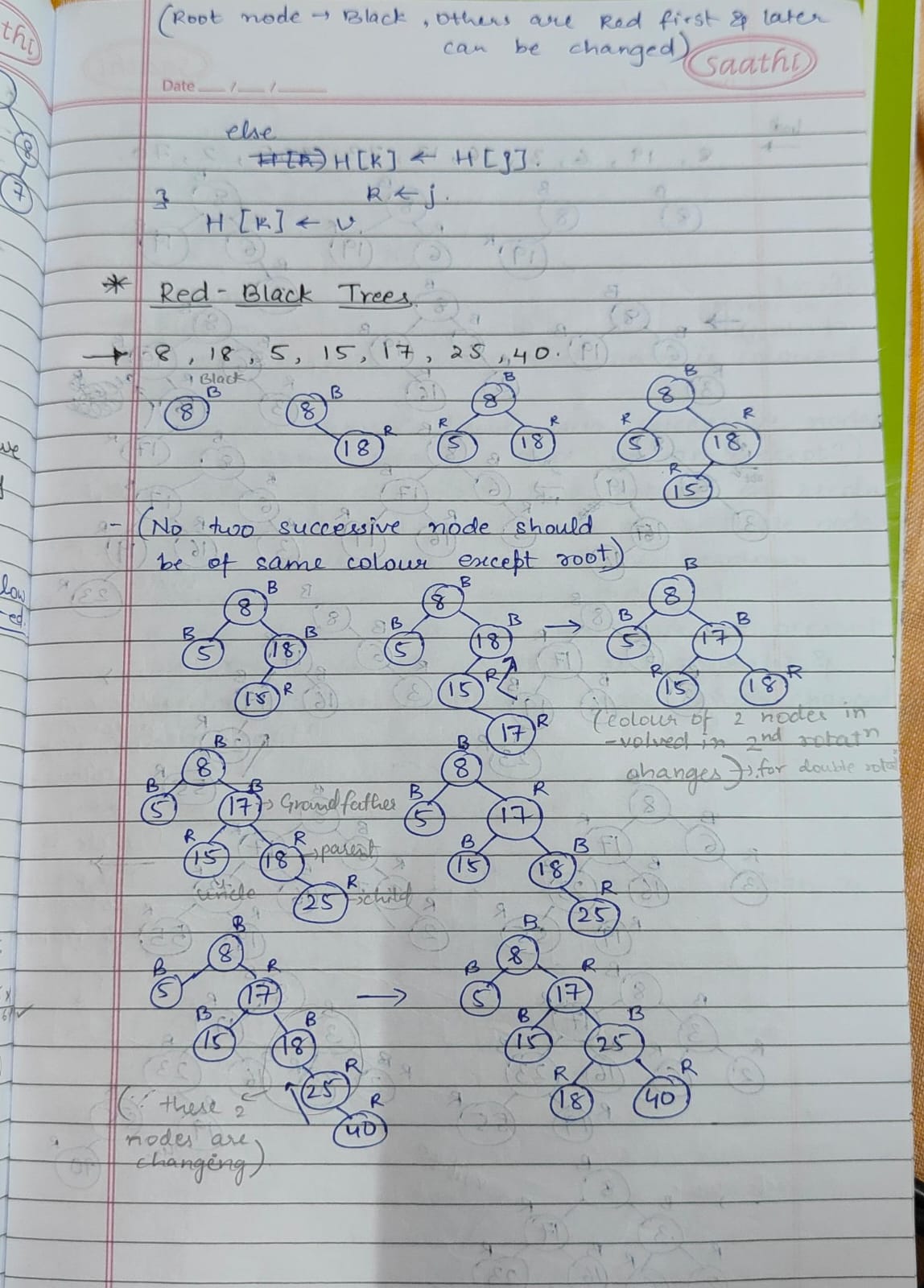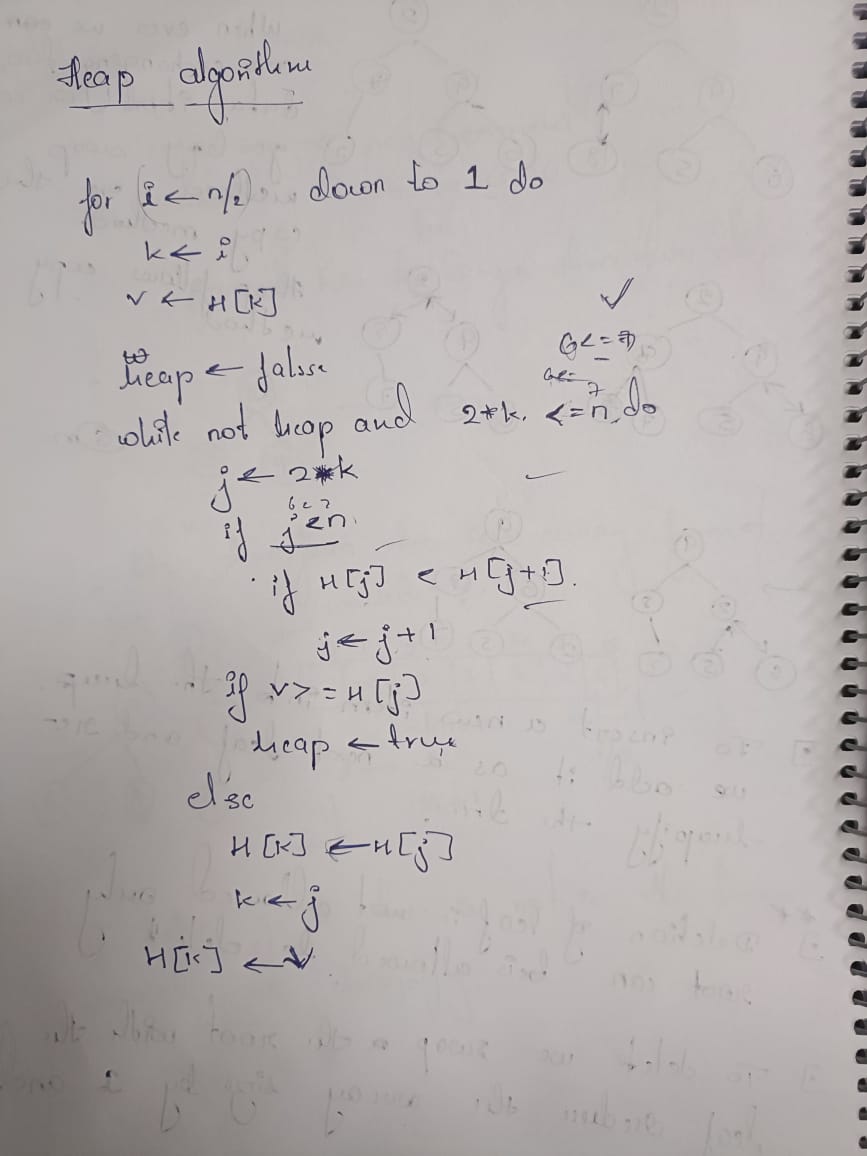Learnings from the Course
Hierarchical Data Structures:
Trees are structured to organize data through parent-child relationships. Binary Search Trees (BST) enable efficient searches, but balancing is essential, achieved through AVL or Red-Black trees. Heaps prioritize task management effectively, while Tries are ideal for operations like prefix matching in auto-complete systems. Each tree type specializes in optimizing specific tasks, making them indispensable across various applications.
Efficient Array Query Algorithms:
Advanced algorithms for array queries tackle problems such as calculating range sums or finding maximum values with remarkable efficiency. Data structures like Segment Trees and Fenwick Trees perform these operations in logarithmic time, making them invaluable in handling large datasets. These techniques find applications in fields like data analytics, competitive programming, and systems requiring real-time calculations.
Comparison of Trees and Graphs:
Trees, being hierarchical and acyclic, are used for organizing structured data such as file systems. Graphs, with their flexible and complex interconnections, are suited for modeling networks and pathways. Tree traversal methods (Inorder, Preorder) are tailored for hierarchical processing, whereas graph traversal techniques (BFS, DFS) excel in exploring connectivity and discovering optimal paths.
Network Optimization Algorithms:
Algorithms for spanning trees, like Kruskal’s, focus on minimizing costs in network infrastructure design. Shortest path algorithms, such as Dijkstra’s, are fundamental in applications like navigation and logistics. These algorithms play a critical role in optimizing connectivity and route planning for real-world networks, improving overall efficiency.